
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 이벤트 매개변수
- 통계
- 용어 정리
- Google Analytics
- git
- 후기
- pandas
- Ga
- 상관계수
- It
- segmentation
- 맞춤 자바스크립트
- 캐글
- SQLD
- tablueau
- 그로스해킹
- Ecommerce
- 데이터 분석
- Funnel
- API
- Kaggle
- 크로스셀링
- DISTINCT
- Python
- 맞춤 이벤트
- oracle
- tableau
- bigquery
- sql 개발자
- SQL
- Today
- Total
녕녀기의 실험일지
[ 그로스해킹 ] 인프런 강의_excel로 구현된 retention + revenue 계산 및 시각화를 Python으로 구현하기 2탄 본문
[ 그로스해킹 ] 인프런 강의_excel로 구현된 retention + revenue 계산 및 시각화를 Python으로 구현하기 2탄
녕녀기 2023. 10. 20. 14:42본문으로
안녕하세요. 녀기입니다.
날씨가 갑자기 추워졌어요ㅠㅠㅠㅠ
저 같이 추위에 취약한 사람들은 옷을 어떻게 입어야 할지 감도 안 온답니다.
(진짜 가을이란 없어...)
이 글을 읽으시는 여러분들도 감기 걸리지 말고 운동 열심히 하시길 바랍니다.

이번 포스팅은 지난 포스팅에서 이어집니다.
↓
https://nyeoki-log.tistory.com/51
[ 그로스해킹 ] 인프런 강의_excel로 구현된 retention + revenue 계산 및 시각화를 Python으로 구현하기
(본문으로) (목차로) 안녕하세요. 녀기입니다. 얼마 전 빅분기 필기가 끝났습니다~~🫡 (모두 쏴리 질러~~~~!!!!!) 굉장히 다행히도 한번에 붙어서 다행이네요ㅠㅠ (여러분들은 모두 합격하셨는지요
nyeoki-log.tistory.com
revenue를 세세하게 쪼개본 뒤 각 지표에 따라 분석할 수 있었습니다.
그렇다면
각 지표가 개선됐을 때 매출에 어떤 영향을 미치는지를 확인하고 싶다면 어떻게 할까요?
사실 모두가 알고 있는 내용입니다ㅋㅋㅋㅋㅋ
숫자를 고쳐서 계산해 보면 됩니다.
excel로 하면 좀 더 간편하게 할 수 있지만,
Python 코드로도 구현해 보겠습니다.
링크를 클릭하시면 제 github로 연결되니까 궁금하신 분들은 들어가 보시길~~
그럼 들어가 보시죠!
지표 개선을 통한 매출 변화

지난 번에 만든 revenue 데이터 프레임을 불러 옵니다.
imp_rev.rename({"Unnamed: 0":"가입 날짜"}, axis=1, inplace=True)
위처럼 컬럼명을 바꿔주고요.
함수를 하나 만들어 볼게요.
def improve_metric(dataframe, join_user : int = 3200, one_after_rt : float = 0.09, imp_rt : float = 0.1,\
one_after_pr : float = 0.5, imp_pr : float = 0.2, arppu : int = 10000) :
"""
잔존율 혹은 결제 비율 개선했을 때 매출 변화량입니다.
- dataframe : revenue를 표시한 pandas 데이터프레임 입니다.
- join_user : 1년 뒤 신규 유저 예상 값 입니다.
- one_after_rt : 1년 뒤 고정된 retention 수치입니다.(0과 1 사이의 실수)
- imp_rt : 개선된 retention 수치입니다.(0과 1 사이의 실수)
- one_after_pr : 1년 뒤 고정된 결제 비율입니다.
- imp_pr : 개선된 결제 비율 수치입니다.
- arppu : 고정된 arppu 입니다.
"""
# import된 라이브러리
import datetime
import copy
df = copy.deepcopy(dataframe)
colList = dataframe.columns
copy_df = copy.deepcopy(dataframe)
# 미래의 지표를 상수로 고정
df.iloc[0:6, 2] = one_after_rt
df.iloc[0:6, 4] = one_after_pr
# 미래에 가입하는 사람을 추가
for i in range(6) :
dt = "2020-"+str(i+1)
df.loc[12+i,colList[0]] = datetime.datetime.strptime(dt, "%Y-%m").strftime("%Y-%m")
# 미래의 ARPPU를 상수로 고정
df.iloc[0:, 6] = arppu
# 미래의 신규 유저를 상수로 고정
df.iloc[-6:,1] = join_user
# 지표가 개선됐을 때 값
for k in range(12) :
bf_rt = copy_df.iloc[k,2]
bf_pr = copy_df.iloc[k,4]
af_rt = bf_rt * (1 + imp_rt)
af_pr = bf_pr * (1 + imp_pr)
if af_rt > 1 :
df.iloc[k+6,2] = 1
else :
df.iloc[k+6,2] = af_rt
if af_pr > 1 :
df.iloc[k+6,4] = 1
else :
df.iloc[k+6,4] = af_pr
# 활동 회원 예상
df[colList[3]] = round(df[colList[1]] * df[colList[2]])
# 결제자수 예상
df[colList[5]] = round(df[colList[3]] * df[colList[4]])
# 매출 예상
df[colList[-1]] = round(df[colList[-3]] * df[colList[-2]])
# 매출 합계 행 추가
len_row = df.shape[0]
df.loc[len_row+1, df.columns[-1]] = df.iloc[:len_row,-1].sum()
df.iloc[-1,0] = '합계'
# 가입 날짜를 인덱스로
df.set_index(df.columns[0], inplace=True)
return df
가볍게 설명하겠습니다.
2019년도 1월부터 12월까지는 모든 자료가 있습니다.
여기서 2020년 상반기의 지표를 개선했을 때 매출을 예상해 보는 것입니다.
2020년 6월까지 예상할 때,
2019년 1월 6월까지의 잔존율, 결제비율, ARPPU는 알 수 없습니다.
왜냐면 실제 기록이 없기 때문입니다.
(19년 1월에게 있어 2020년 6월은 이미 1년 6개월 지난 뒤 지표이기 때문이죠.)
그래서 우리는 이 3가지 지표를 임의의 상수로 가정합니다.
시간이 지났을 때는 상수 정도의 값으로 고정되지 않을까?
하는 생각인 것이죠.
같은 이치로 2020년 1월부터 6월까지 신규 유입도 상수로 가정합니다.
기록이 없으니까요.
그럼 2019년 7월부터는 어떻게 될까요?
2019년 7월은 2020년 6월에서 봤을 때, 딱 1년 지난 것입니다.
1년이 지났을 때 잔존율은 알 수 있습니다.
바로 2019년 1월에서 잔존율 기록이 남아있기 때문이죠.
심지어 잔존율을 개선한다고 했으니
2019년 1월의 잔존율을 개선된 수치와 함께 계산해서 입력하면 됩니다.
약 14%였고, 잔존율 개선 비율을 10% 정도로 잡았으므로,
0.14 * (1 + 0.1) = 0.154
약 15% 정도로 잔존율이 증가했다고 가정합니다.
같은 방식으로 19년 8월은 19년 2월에서 잔존율을 개선하면 되겠습니다.
결제 비율도 위와 같이 계산해 주고,
계산된 수치에 따라 활동회원과 결제자 수도 계산할 수 있습니다.
매출은 계산된 (결제자 수 * ARPPU)를 계산하면 됩니다.
그러면 아래와 같이
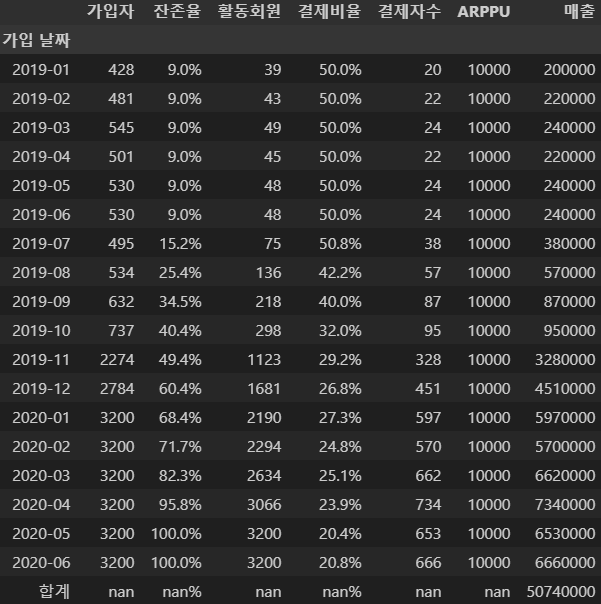
예상되는 매출을 확인할 수 있습니다.
잔존율을 기존에서 12% 개선시키고 싶다면
future_metric_rt12 = improve_metric(dataframe=imp_rev, imp_rt=0.12)파라미터의 수를 바꿔주면 되겠죠?
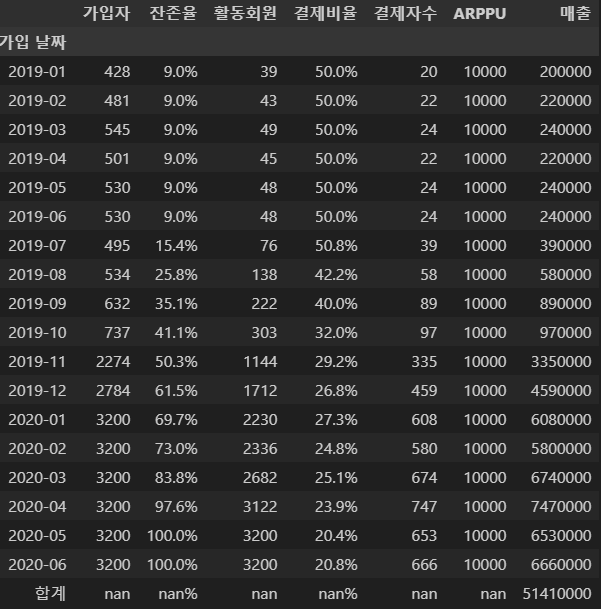
잔존율이 올랐으니 매출도 당연히 올랐습니다.
약 1.3%로 올랐네요.
이런 식으로 어떤 퍼널을 개선시키는 것이 매출에 강하게 영향을 미치는지 파악할 수 있습니다.
후....정말 세상에는 배울 것이 너무 많습니다.
그래도 항상 새로운 개념을 알게 되는 것은 재밌죠!!
적응하기까지가 쉽지 않지만

쨌든 나름 잘 적용해 본 것 같으니
저는 다시 일상으로 도망갈게요~~
다음에 봬요~~

'-- Data -- > - 데이터 분석 -' 카테고리의 다른 글
| [ 후기 ] 빅데이터 분석 기사 후기 (0) | 2023.12.15 |
|---|---|
| [ 통계 ] 독립 표본 t-검정과 대응 표본 t-검정의 차이 (0) | 2023.11.07 |
| [ 실생활에서 고찰 ] 테스트 - 이항 분포와의 관계 (0) | 2023.10.18 |
| [ 그로스해킹 ] 인프런 강의_excel로 구현된 retention + revenue 계산 및 시각화를 Python으로 구현하기 (0) | 2023.10.13 |
| [ Data ] 퍼널 분석(Funnel Analysis)이란? (0) | 2023.07.03 |



