
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 후기
- bigquery
- oracle
- 크로스셀링
- 이벤트 매개변수
- 데이터 분석
- 그로스해킹
- Kaggle
- API
- Python
- SQL
- 맞춤 자바스크립트
- sql 개발자
- Ga
- pandas
- Funnel
- tableau
- Google Analytics
- SQLD
- tablueau
- Ecommerce
- 맞춤 이벤트
- segmentation
- 상관계수
- 통계
- 용어 정리
- It
- DISTINCT
- 캐글
- git
- Today
- Total
녕녀기의 실험일지
[ kaggle ] cosmetics ecommerce 분석 : RFM 고객 세분화 분석 본문
목차
4. BigQuery로 일부 데이터 RFM 고객 세분화
1. 개요
- 가격 데이터가 음수인 데이터 처리 여부 결정
- 해당 분석을 위해 Python 코드로 구현
- BigQuery를 통해, SQL로 RFM 쿼리 일부 구현
- RFM(Recency, Frequency, Monetary) 분석을 위한 기준을 정함
- '관심 필요 최고 충성 고객'은 '최고 충성 고객'에 준하는 서비스 제공이 필요하다고 생각
2. EDA
df = csv_to_df('ecommerce_data_2019-2020.csv')
df.info()
df.head()
# 통계치 확인
df.describe(include='all')
위 코드를 통해 통계치를 확인했을 때, 가격이 음수인 부분을 확인할 수 있었습니다.

제품 가격이 음수인 이유를 두 가지 정도 생각해 볼 수 있습니다.
1). 특정 제품이나 일정 가격 구매시, 해당 제품의 할인을 음수로 표현했다.
2). 오류이다.
1) 검증을 위해 가격이 음수인 제품이 가격 변화를 살펴 봤습니다.
# price가 음수인 경우?
neg_price = df[df['price'] < 0]
# 연월일만 추출
neg_price['event_time_ymd'] = neg_price['event_time'].dt.strftime('%Y-%m-%d')
# 날짜에 따른 가격 변동 확인(해당 제품은 계속 음수인가?)
neg_id = neg_price['product_id'].unique()
fig, axes = plt.subplots(figsize=(8,20), nrows=len(neg_id), ncols=1)
for i in tqdm(range(len(neg_id))) :
df_neg_id_i = neg_price[neg_price['product_id'] == neg_id[i]]
axes[i].plot_date(x=df_neg_id_i['event_time'], y=df_neg_id_i['price'])
axes[i].set_title(f'price trends of product_id_{neg_id[i]}')
axes[i].set_ylabel('$')
plt.show()
제품의 가격이 시간이 지나도 일정한 것을 알 수 있습니다. 이 제품은 적어도 이 데이터 셋 안에서는 양수였던 적이 없다는 뜻입니다. 할인의 개념으로 제품 가격을 음수로 계산했는지 확인하기 위해, 음수 제품을 구매했던 사용자들의 총 구매 금액을 살펴 보겠습니다.
# 가격이 음수인 제품이랑 같이 구매된 제품은?
df_neg_id = df[df['product_id'].isin(neg_id)]
neg_session = df_neg_id['user_session'].unique()
neg_user = df_neg_id['user_id'].unique()
df_neg_purchase = df[(df['user_session'].isin(neg_session)) & (df['user_id'].isin(neg_user)) & (df['event_type']=='purchase')]
# user_id별, user_seesion별 총 구매 금액
neg_sum = df_neg_purchase.groupby(['user_id', 'user_session'])['price'].sum().reset_index(level=[0,1], drop=False)
plt.rcParams['font.family'] = 'NanumBarunGothic'
plt.plot(neg_sum['user_id'], neg_sum['price'])
plt.plot(neg_sum['user_id'], [0 for i in range(neg_sum['price'].shape[0])], color='r', linestyle='dashed')
plt.title('가격이 음수인 제품과 같이 구매한 제품들의 총 금액')
plt.xlabel('user_id')
plt.ylabel('sum price')
plt.show()
붉은 선은 구매 금액이 0인 지점인데 총 구매 금액이 음수인 지점을 확인할 수 있습니다. 만약 할인의 개념으로 가격을 음수로 표현했다면, 총 구매 금액이 음수인 경우는 없어야 한다고 생각합니다. 따라서 해당 제품의 가격은 오류로 판단되므로 RFM 고객 세분화 분석에서 제외하도록 하겠습니다.
3. Python 코드로 RFM 고객 세분화
# 가격이 양수가 아닌 이벤트의 비율
df[df['price'] <= 0].shape[0] / df.shape[0]
# >> 0.005039810871779804
가격이 음수인 데이터는 전체 데이터의 0.05% 정도이므로 제외하겠습니다.
# 비율이 전체 이벤트 데이터에 0.5% 이므로 제거해도 무방하다고 판단
df2 = df[df['price'] > 0]
df2.reset_index(drop=True, inplace=True)
그리고 RFM 고객 세분화를 위한 코드를 Python으로 작성해 보겠습니다.
2020년 3월 1일에 분석을 진행한다고 가정했을 때, 3월 1일 이전 데이터에서 가장 최근에 발생한 Purchase의 날짜를 추출하겠습니다.
# 2020년 3월 1일을 기준으로 사용자의 rfm을 계산
class rfm :
def __init__(self, dataframe, ts : str = '2020-03-01 00:00:00'):
self.ts = ts
dataframe2 = dataframe[(dataframe['event_type'] == 'purchase') & (dataframe['event_time'] <= pd.Timestamp(self.ts, tz='UTC'))]
dataframe2['event_time1'] = dataframe2['event_time'].dt.strftime('%Y-%m-%d')
dataframe2['event_time2'] = dataframe2['event_time'].dt.strftime('%Y-%m')
dataframe2.sort_values(by='event_time', ascending=True, inplace=True)
self.dataframe = dataframe2
def recent_date(self) :
df_recency = self.dataframe.drop_duplicates(subset='user_id', keep='last')
df_recency = df_recency[['user_id', 'event_time']]
df_recency.rename(columns={'event_time' : 'recency'}, inplace=True)
df_recency.reset_index(drop=True, inplace=True)
self.df_recency = df_recency
return self.df_recency
def count_active(self) :
# 사용자별, 일별로 제품의 구매 여부를 count
df_frequency = self.dataframe.drop_duplicates(subset=['user_id', 'product_id', 'event_time1'], keep='last')
df_frequency = df_frequency.groupby(['user_id', 'product_id'])['event_time1'].count()
df_frequency = df_frequency.reset_index(level=[0, 1], drop=False).groupby(['user_id'])['event_time1'].sum()
df_frequency.rename('frequency', inplace=True)
df_frequency = df_frequency.reset_index(drop=False)
self.df_frequency = df_frequency
return self.df_frequency
def sum_price(self) :
df_sum = self.dataframe.groupby('user_id')['price'].sum()
df_sum.rename('monetary', inplace=True)
df_sum = df_sum.reset_index(drop=False)
self.df_sum = df_sum
return self.df_sum
def join_rfm(self) :
df_recency = self.recent_date()
df_frequency = self.count_active()
df_sum = self.sum_price()
df_join = df_recency.merge(df_frequency, on='user_id').merge(df_sum, on='user_id')
df_join = df_join.sort_values(by=['frequency', 'monetary', 'recency'], ascending=[False, False, False], axis=0)
self.df_join = df_join
return self.df_join
# rfm table
df_rfm = rfm(df2).join_rfm()
df_rfm.info()
df_rfm.head()

위와 같이 테이블을 구축할 수 있습니다.
4. BigQuery로 일부 데이터 RFM 고객 세분화
이번에는 위 과정과 동일하게 BigQuery로 RFM 고객 세분화를 진행해 보겠습니다. 2019년 10월 데이터만 사용해 보겠습니다.
with data_rfm as (
select event_time, user_id, product_id, event_type, price
from `kaggle-ecommerce-419203.ecommece_data.2019-Oct`
where 1=1
and event_type = 'purchase'
and event_time < '2020-03-01 00:00:00'
and price > 0
)
, recency as (
select user_id
,max(event_time) as recency
from data_rfm
group by user_id
)
, frequency as (
select user_id
, sum(frequency) as frequency
from (
select user_id
, product_id
, count(distinct format_date('%Y-%m-%d', event_time)) as frequency
from data_rfm
group by user_id, product_id
)
group by user_id
)
, monetary as (
select user_id,
sum(price) as monetary
from data_rfm
group by user_id
)
select r.user_id as user_id
, r.recency as recency
, f.frequency as frequency
, m.monetary as monetary
from recency r
inner join frequency f
on r.user_id = f.user_id
inner join monetary m
on r.user_id = m.user_id
order by frequency desc, monetary desc, recency desc
;

5. 고객 세분화 기준 세우기
고객 세분화의 기준은 다음과 같이 설정하려고 합니다.
- 통계치를 보고 임의로 구간을 나눈 뒤, 고객 세분화
- 군집(clustering) 기법을 활용하여, 고객 세분화
- KMeans 활용
- DBSCAN 활용
위 과정은 CRM을 담당하는 부서와 협의 끝에 설정한 기준이라고 가정하겠습니다.
5 - 1. 통계치를 보고 임의의 구간을 나눔
# recency, frequncy, monetary를 boxplot으로 표현
col_list = ['recency', 'frequency', 'monetary']
fig, axes = plt.subplots(figsize = (15, 6), nrows=1, ncols=3)
for i in range(3) :
col = col_list[i]
ax = axes[i]
if col == 'recency' :
ax.boxplot(df_rfm[col].astype(int))
ax.set_ylabel('datetime to int')
else :
ax.boxplot(df_rfm[col])
if col == 'frequency' :
ax.set_ylabel('#')
elif col == 'monetary' :
ax.set_ylabel('$')
ax.set_title(f'box plot of {col}')
plt.show()

recency는 정규분포에 가까운 형태를 하고 있고, frequency와 monetary는 오른꼬리가 긴 극단적인 형태를 하고 있습니다. frequency와 monetary가 높은 사람들은 이상치로 취급될만큼 보통 사용자와 극명한 차이를 보이는 것으로 확인됩니다.
위 통계치와 조사 결과를 통해 고객 세분화의 기준을 세워보겠습니다.
보통 recency의 기준을 사내에서 정한 이탈 기준으로 정할 수 있지만, 해당 데이터로 이탈 기준을 정할 수는 없습니다. 따라서, recency의 기준은 3개월 기준으로 나누겠습니다.
3개월인 이유는, 앞선 프로젝트에서 첨부한 조사 결과에서 2~3개월마다 적어도 1회 화장품을 구입하는 비율이 42%이기 때문입니다. 약 절반 정도의 사람이 2~3개월에 한번씩 화장품을 구매한다면, 3개월이 지나도 활성화되지 않은 사용자는 이탈로 판단할 수 있을 것이라고 생각합니다.
(사내에서 정한 이탈 기준이 있다면 해당 기준을 따릅니다.)
( iqr = 3사분위수 - 1사분위수 )
recency 분류
- 최근 접속일이 3개월 이내일 경우, RECENT
- 최근 접속일이 3개월을 초과했을 경우, PAST
frequency의 기준은 frequency의 3사분위수를 기준으로 하겠습니다.
frequency 분류
- 활성 빈도가 13(3사분위수) 이상인 경우, HIGH
- 활성 빈도가 13(3사분위수) 미만인 경우, LOW
monetary는 monetary의 1사분위수와 3사분위수로 iqr(3사분위수 - 1사분위수)을 계산하여 기준을 정하겠습니다.
monetary 분류
- 총 결제 금액이 3사분위수 + 1.5iqr 이상인 경우, HIGH
- 총 결제 금액이 33.22(2사분위수) 이상이고 3사분위수 + 1.5iqr 미만인 경우, MIDDLE
- 총 결제 금액이 33.22(2사분위수) 미만인 경우, LOW
monetary만 3가지로 분류하는 이유는 총 결제 금액이 frequency 보다 중요하다고 생각하기 때문입니다. 모든 고객이 동등하지 않기 때문에, (3사분위수 + 1.5iqr) 이상의 금액을 쓰는 사용자를 상위 등급으로 표현하고자 합니다.
위 기준으로 나눴을 때 고객을 12가지로 분류할 수 있습니다.
1. R = RECENT, F = HIGH, M = HIGH : 최고 충성 고객
2. R = RECENT, F = LOW, M = HIGH : 충성 고객
3. R = RECENT, F = HIGH, M = MIDDLE : 충성 고객
4. R = RECENT, F = HIGH, M = LOW : 일반 고객
5. R = RECENT, F = LOW, M = MIDDLE : 일반 고객
6. R = RECENT, F = LOW, M = LOW : 신규 고객
7. R = PAST, F = HIGH, M = HIGH : 관심 필요 최고 충성 고객
8. R = PAST, F = LOW, M = HIGH : 관심 필요 충성 고객
9. R = PAST, F = HIGH, M = MIDDLE : 관심 필요 충성 고객
10. R = PAST, F = HIGH, M = LOW : 이탈 위험 고객
11. R = PAST, F = LOW, M = MIDDLE : 이탈 위험 고객
12. R = PAST, F = LOW, M = LOW : 이탈 고객
12가지 경우의 수를 통해, 고객을 8개로 분류할 수 있었습니다.
'최고 충성 고객', '충성 고객', '일반 고객', '신규 고객', '관심 필요 최고 충성 고객', '관심 필요 충성 고객', '이탈 위험 고객', '이탈 고객'
으로 고객을 분류해 보겠습니다.
# rfm을 분류하기
df_des = df_rfm.iloc[:, 1:].describe(include='all')
# iqr 계산
iqr = df_des.loc['75%', 'monetary'] - df_des.loc['25%', 'monetary']
max_monetary = df_des.loc['75%', 'monetary'] + 1.5 * iqr
# 한 달을 28일로 두고, 3월 1일에서 84일 차이를 기준으로 recency를 나눔
df_rfm['class_recency'] = df_rfm.apply(lambda x : 'RECENT' if (pd.Timestamp('2020-03-01 00:00:00', tz='UTC') - x['recency']).days <= 84 else 'PAST', axis=1)
df_rfm['class_frequency'] = df_rfm['frequency'].apply(lambda x : 'HIGH' if x >= df_des.loc['75%', 'frequency'] else 'LOW')
def class_mon(row) :
if row['monetary'] >= max_monetary :
return 'HIGH'
elif df_des.loc['50%', 'monetary'] <= row['monetary'] < max_monetary :
return 'MIDDLE'
else :
return 'LOW'
df_rfm['class_monetary'] = df_rfm.apply(class_mon, axis=1)# 분류된 rfm을 통해 고객 분류
def segment_user(row) :
if row['class_recency'] == 'RECENT' :
if row['class_frequency'] == 'HIGH' and row['class_monetary'] == 'HIGH' :
return '최고 충성 고객'
elif (row['class_frequency'] == 'LOW' and row['class_monetary'] == 'HIGH') or (row['class_frequency'] == 'HIGH' and row['class_monetary'] == 'MIDDLE'):
return '충성 고객'
elif (row['class_frequency'] == 'HIGH' and row['class_monetary'] == 'LOW') or (row['class_frequency'] == 'LOW' and row['class_monetary'] == 'MIDDLE'):
return '일반 고객'
else :
return '신규 고객'
elif row['class_recency'] == 'PAST' :
if row['class_frequency'] == 'HIGH' and row['class_monetary'] == 'HIGH' :
return '관심 필요 최고 충성 고객'
elif (row['class_frequency'] == 'LOW' and row['class_monetary'] == 'HIGH') or (row['class_frequency'] == 'HIGH' and row['class_monetary'] == 'MIDDLE'):
return '관심 필요 충성 고객'
elif (row['class_frequency'] == 'HIGH' and row['class_monetary'] == 'LOW') or (row['class_frequency'] == 'LOW' and row['class_monetary'] == 'MIDDLE'):
return '이탈 위험 고객'
else :
return '이탈 고객'
df_rfm['segmentation'] = df_rfm.apply(segment_user, axis=1)
df_rfm.head()
5 - 2. 군집 기법 활용
KMeans와 DBSCAN에 대해서 간단하게 살펴보겠습니다.
KMeans는 군집 내 크기와 군집 간 거리를 통해 군집을 분류합니다. 군집 내에서 분류된 데이터의 거리는 가까울수록, 군집 간의 거리는 클수록 좋습니다. 보통 군집을 원형으로 분류합니다.
DBSCAN은 가깝고 연결돼 있는 데이터끼리 군집을 분류합니다. 비원형의 데이터를 군집화하는데 좋고, 이상치가 포함돼 있어도 군집화하는 기능이 뛰어납니다.
먼저 KMeans기법을 사용하기 위해 RFM 테이블을 전처리 해 줍니다.
df_rfm2 = df_rfm[['user_id','recency', 'frequency', 'monetary']]
# 2020년 3월 1일과의 날짜 차이를 계산
df_rfm2['recency_diff'] = (pd.Timestamp('2020-03-01 00:00:00', tz='UTC') - df_rfm2['recency']).dt.days
그 후 RobustScaler를 사용해 변수를 변환해 줍니다.
(해당 Scaler를 사용한 이유는 frequency와 monetary의 데이터 분포가 꼬리가 긴 분포이기 때문입니다.)
(정규 분포 X)
from sklearn.preprocessing import RobustScaler
r_scale = RobustScaler()
r_scale.fit(df_rfm2.iloc[:,2:])
X_train = r_scale.transform(df_rfm2.iloc[:,2:])
그 후 elbow method를 사용해 비용이 급격하게 줄어드는 구간을 확인해 봅니다.
# elbow method에서 비용함수가 급격히 줄어드는 k 찾기
from yellowbrick.cluster import KElbowVisualizer
k=0
kmeans = KMeans(n_clusters=k, random_state=26)
visualizer = KElbowVisualizer(kmeans, k=(1,12), timings=False)
visualizer.fit(X_train)
visualizer.show()
또한 실루엣 계수도 계산해 적합한 k값을 찾아봅니다.
# 실루엣 계수로 찾기
from sklearn.metrics import silhouette_score
for k in range(2, 12):
kmeans = KMeans(n_clusters=k, random_state=26).fit(X_train)
silhouette_avg = silhouette_score(X_train, kmeans.labels_)
print(f'cluster : {k} // silhouette index {silhouette_avg}')
# >> cluster : 2 // silhouette index 0.7872550662319724
# >> cluster : 3 // silhouette index 0.6551884792548721
# >> cluster : 4 // silhouette index 0.5685331191800215
# >> cluster : 5 // silhouette index 0.4716960015948851
# >> cluster : 6 // silhouette index 0.41203076733370236
# >> cluster : 7 // silhouette index 0.3325260195410557
# >> cluster : 8 // silhouette index 0.33346292507591235
# >> cluster : 9 // silhouette index 0.3386224883311785
# >> cluster : 10 // silhouette index 0.3347089984395965
# >> cluster : 11 // silhouette index 0.336696553370974
elbow method와 실루엣 계수를 통해 적절한 k 값이 '3'임을 알았습니다. 하지만 다양한 소비 패턴을 보이는 고객들을 겨우 3가지 고객군으로 분류하는 것은 적합한 전략이 아니라고 판단됩니다.
다음은 DBSCAN을 통해 군집화를 진행해 보겠습니다.
DBSCAN의 하이퍼 파라미터 중 eps는 KNN(K Nearest Neighbor) 기법을 활용하여 이웃 간 거리가 급격히 증가하는 거리를 파라미터 값으로 사용합니다.
# knn으로 eps 값 찾기
from sklearn.neighbors import NearestNeighbors
# K-NN 거리 계산
k = 5
nbrs = NearestNeighbors(n_neighbors=k).fit(X_train)
distances, indices = nbrs.kneighbors(X_train)
# k번째 이웃까지의 거리 정렬
distances = np.sort(distances[:, k-1], axis=0)
# K-NN 거리 그래프 그리기
plt.plot(distances)
plt.xlabel('Data Points sorted by distance')
plt.ylabel('k-NN distance')
plt.title('K-NN distance graph')
plt.show()
눈으로 어림 잡아 거리가 '1'인 시점부터 급격히 증가하는 것으로 보입니다. 따라서 eps를 약 1로 대입해 군집화를 진행하겠습니다. 이후 군집화된 데이터를 3D로 시각화 해 봤습니다.
from sklearn.cluster import DBSCAN
from mpl_toolkits.mplot3d import Axes3D
# 1 이상인 값 중 최소값
arr_eps = distances[np.where(distances > 1)][0]
# DBSCAN 클러스터링 수행
db = DBSCAN(eps=arr_eps, min_samples=k).fit(X_train)
# 결과 시각화
labels = db.labels_
df_rfm2['cluster'] = labels
fig = plt.figure(figsize=(10, 10))
plt.rcParams['font.family'] = 'NanumBarunGothic'
ax = fig.add_subplot(111, projection='3d')
# 3D 산점도
for cluster in df_rfm2['cluster'].unique():
cluster_data = df_rfm2[df_rfm2['cluster'] == cluster]
ax.scatter(cluster_data['frequency'], cluster_data['monetary'], cluster_data['recency_diff'],
alpha=1, label=f'Cluster {cluster}')
# 축 레이블 설정
ax.set_xlabel('frequency')
ax.set_ylabel('monetary')
ax.set_zlabel('recency_diff')
plt.show()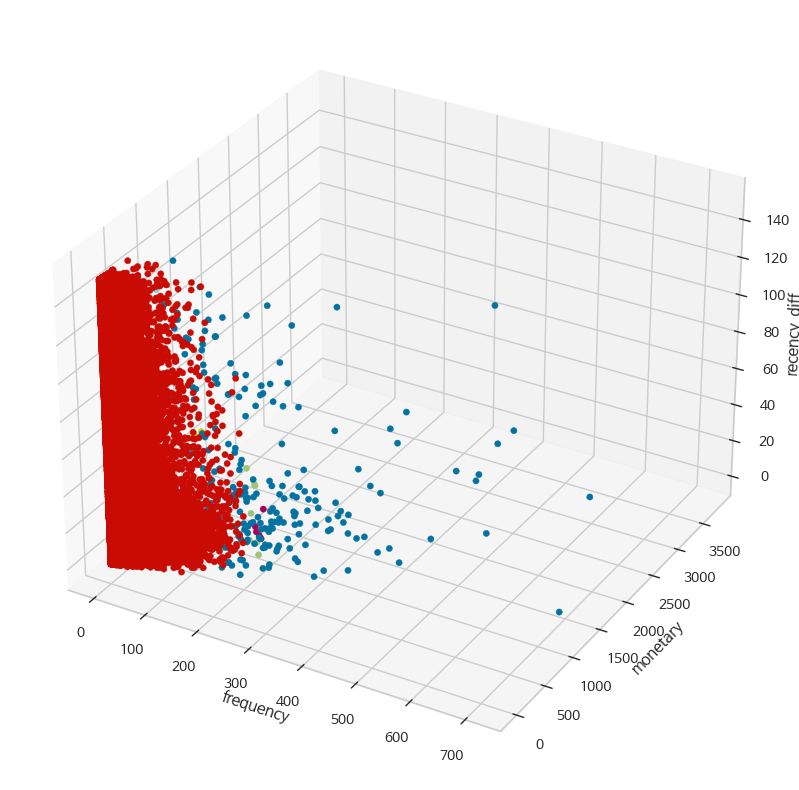
Fig 12를 봤을 때, 빨간색으로 분류된 데이터가 너무 많은 것 같습니다.
테이블을 통해 다시 살펴보면,

cluster 1에 해당하는 사용자가 압도적으로 많으므로(전체 고객의 99%), 올바르게 분류됐다고 볼 수 없습니다.
따라서 KMeans와 DBSCAN으로 고객 세분화를 하지 않고, 4 - 1에서 분류했던 방법으로 고객을 분류하는 것이 적합해 보입니다.
6. 분석 / 인사이트
각 고객군별로 분류된 사용자의 수와 고객군별 총 매출액을 한번 살펴보겠습니다.
# rfm group by
df_rfm_gr = df_rfm.groupby('segmentation').agg({'user_id' : 'count', 'monetary':'sum'}).reset_index(drop=False).sort_values('monetary', ascending=False)
# 매출 총합
sum_sales = df_rfm_gr['monetary'].sum()
df_rfm_gr['cum_sum'] = df_rfm_gr['monetary'].cumsum() # 누적합
df_rfm_gr['ratio'] = df_rfm_gr['cum_sum'] / sum_sales * 100 # 누적합 / 전체 매출
# 이전 행과 차이가 전체 매출에서 얼마만큼 차지하는지 비율
df_rfm_gr['ratio_diff'] = (df_rfm_gr['monetary'].diff() * -1).fillna(0) / sum_sales * 100
df_rfm_gr
위 테이블을 pareto chart로 표현해 보겠습니다.
fig, ax1 = plt.subplots(figsize=(15,6))
plt.rcParams['font.family'] = 'NanumBarunGothic'
ax1.bar(df_rfm_gr['segmentation'], df_rfm_gr['monetary'], color='#B3F6FF')
ax1.set_title('고객 세분화에 따른 매출 파레토 그림')
ax1.set_ylabel('매출액 ($)')
ax2 = ax1.twinx()
ax2.plot(df_rfm_gr['segmentation'], df_rfm_gr['ratio'], color='#C485FF')
ax2.set_ylabel('%')
for i in range(df_rfm_gr['segmentation'].shape[0]):
ax2.text(df_rfm_gr['segmentation'][i], df_rfm_gr['ratio'][i], str(round(df_rfm_gr['ratio'][i],1))+'%', ha='center', va='bottom')
ax2.text(df_rfm_gr['segmentation'][i], df_rfm_gr['ratio'][i], '(-'+str(round(df_rfm_gr['ratio_diff'][i],1))+'%)', ha='center', va='top')
plt.show()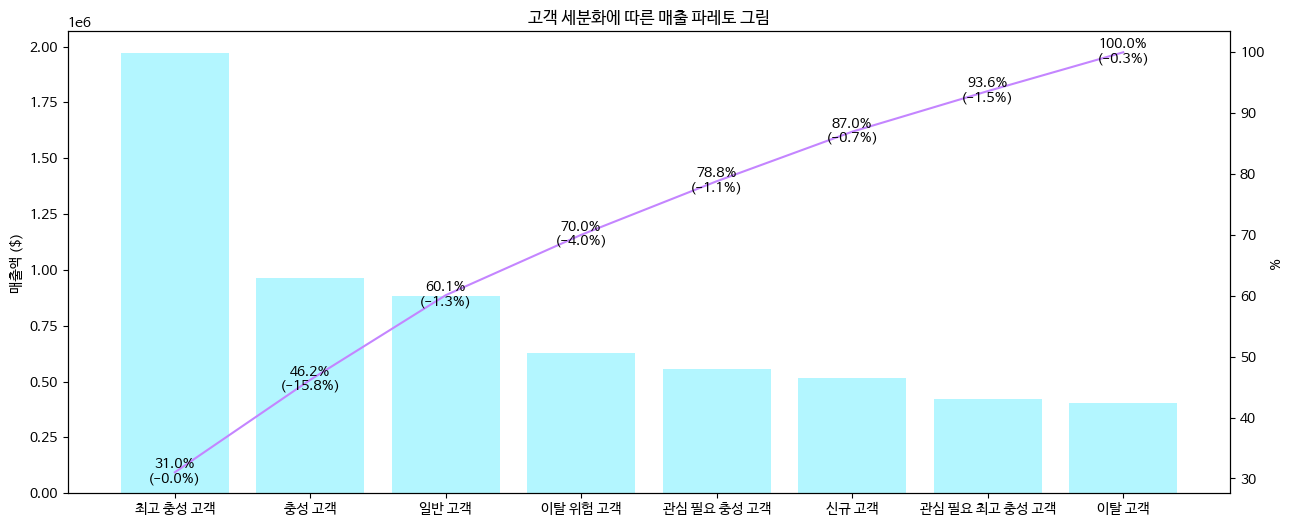
Fig 10과 Fig11을 보면, 당연하게도 최고 충성 고객의 매출이 전체 매출의 30%를 차지할 정도로 많습니다. 매출의 약 80%를 차지하는 고객군은 관심 필요 충성 고객까지라고 볼 수 있을 것 같습니다.
충성 고객에 가깝게 분류할 수록 구매에 대한 망설임이 적을 것이라고 생각합니다.
세분화된 고객 분류별로 purchase / view 이벤트 비율을 살펴보면,
# 5개월간 ecommerce 데이터에서 일부 컬럼만 추출
df_ver_mer = df[['event_time', 'event_type', 'product_id', 'user_id', 'user_session']]
# rfm 테이블에서 일부 컬럼만 추출
df_rfm_ver_mer = df_rfm[['user_id', 'segmentation']]
# merge
df_mer = pd.merge(left = df_ver_mer, right = df_rfm_ver_mer, on = 'user_id', how='inner')
# group by
df_mer_gr = df_mer.groupby(['segmentation', 'event_type'])['user_session'].count().reset_index(level=[0,1], drop=False)
# pivot
df_mer_gr = df_mer_gr.pivot(index = 'segmentation', columns='event_type', values='user_session')[['view', 'purchase']].sort_values('purchase', ascending=False)
카이제곱 독립성 검정을 통해 세분화된 고객 분류와 이벤트 발생 간의 독립성을 살펴보겠습니다.
# 카이제곱 검정을 통한 독립성 검정
chi2 = chi2_contingency(observed=df_mer_gr)
# 유의수준 5%에서
if chi2[1] < 0.05 :
print(f'유의수준 5%에서 p-value가 {chi2[1]}이므로 귀무가설 기각, 고객 분류와 view / purchase 이벤트 간의 상관성이 있을 수도 있습니다.')
else :
print(f'유의수준 5%에서 p-value가 {chi2[1]}이므로 귀무가설 채택, 고객 분류와 view / purchase 이벤트는 독립적입니다.')
# >> 유의수준 5%에서 p-value가 0.0이므로 귀무가설 기각, 고객 분류와 view / purchase 이벤트 간의 상관성이 있을 수도 있습니다.
해당 검정을 통해 세분화된 고객 분류와 이벤트 발생 간의 상관성이 있을지도 모른다고 판단했습니다. 이벤트의 발생 비율을 시각화 해보면,
df_mer_gr['purchase / view'] = df_mer_gr['purchase'] / df_mer_gr['view'] * 100
plt.rcParams['font.family'] = 'NanumBarunGothic'
fig = plt.figure(figsize=(15,8))
plt.barh(y=df_mer_gr.sort_values(by='purchase / view',ascending=True).index, width = df_mer_gr['purchase / view'].sort_values(ascending=True))
plt.title('고객 세분화별 purchase / view (%)')
plt.xlabel('%')
plt.show()
충성 고객일 수록 purchase 이벤트 비율이 높다는 것을 확인할 수 있습니다.
다만 Fig 11과 Fig 13을 통해 특이한 점을 발견할 수 있었습니다. '관심 필요 최고 충성 고객'이 높은 purchase 이벤트 발생율을 보인다는 것입니다. 해당 고객들이 활발히 구매를 하고 접속을 하지 않는 이유는, 2019년 11월에 있었던 것으로 추정되는 할인 이벤트에서 충분한 구매를 했기 때문으로 생각됩니다.
'관심 필요 최고 충성 고객'의 마지막 접속일로 히스토그램을 그려보면,
df_need_att = df_mer[(df_mer['segmentation'] == '관심 필요 최고 충성 고객') & (df_mer['event_type'] == 'purchase')][['event_time', 'user_id', 'segmentation']]
df_need_att['ymd'] = df_need_att['event_time'].dt.strftime('%Y-%m-%d')
df_need_att = df_need_att.groupby('user_id')['ymd'].max().reset_index(drop=False)
import matplotlib.dates as mdates
# datetime 데이터를 숫자로 변환
df_need_att['ymd_num'] = mdates.date2num(df_need_att['ymd'])
fig, ax = plt.subplots(figsize=(15,6), nrows=1, ncols=1)
plt.rcParams['font.family'] = 'NanumBarunGothic'
ax.hist(df_need_att['ymd_num'], bins=10, alpha=1, color='#B8FFCC')
# x축을 datetime 형식으로 설정
ax.xaxis.set_major_locator(mdates.MonthLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.set_title('관심 필요 최고 충성 고객의 마지막 접속일 histogram')
ax.set_ylabel('#')
plt.show()
상당수의 고객들이 11월 말부터 12월 초까지만 접속 후 더이상 활동하지 않는 것을 확인할 수 있습니다.
관심 필요 최고 충성 고객은 현재 활동을 하지 않아 총 매출은 적지만, 제품을 구매하는데 있어 주저함이 없는(고민하는 시간이 적은) 고객군이라고 생각이 듭니다.
"따라서, 이탈 가능성이 있는 고객군 중 '관심 필요 최고 충성 고객'은 취향에 적합한 제품이라면 바로 구매할 수 있도록, 푸시나 메시지, 이메일에 제품 추천이 필요할 것으로 생각됩니다. 또한 '최고 충성 고객'에게 제공하는 서비스(포인트나 할인 쿠폰, 사은품 등)에 준하는 서비스를 제공할 것이라는 내용을 포함하는 것도 고려해야 한다고 생각합니다."
7. 배운 점, 어려웠던 점
7 - 1. 배운 점
RFM에 대한 개념을 배웠고, SQL과 Python으로 분류하는 방법을 익힐 수 있었습니다. 특히 SQL과 Python에서 동등한 결과가 나오는 것을 보고, 의도한대로 잘 만든 것 같다는 생각을 가지게 됐습니다.
군집 분석에 대한 기법을 사용해 볼 수 있었습니다. 예전부터 KMeans를 주로 사용해 왔지만, 비교를 위해 DBSCAN도 사용해 봤습니다. 군집 평가하는 방식이 두 기법이 다르다는 것을 알게 됐습니다. 비록 두 방법으로 고객을 세분화할 수는 없었지만, 적절한 상황이 생겼을 때 군집화를 통해 분류할 수 있을 것 같습니다.
7 - 2. 어려웠던 점
고객을 세분화하는 기준을 세우는 것이 어려웠습니다. Recency의 경우 3개월을 기준으로 나눴지만, 실제 고객이 3개월만에 이탈했다고 볼 수는 없었습니다. 사내에서 이탈의 기준을 정하는 것의 중요성을 느꼈습니다.
처음 Frequency 기준을 세울 때 MAU를 기준으로 정할까 고민했었습니다. 하지만 최소 Active가 1회, 최대 Active가 5회였기 때문에 고객을 구분하기에는 적합하지 않다는 것을 알았습니다. DAU를 사용하고 싶었지만, MAU와 DAU가 같은 고객이 많았기 때문에 DAU도 사용할 수 없었습니다. 이후 같은 제품이라도 여러 날짜로 나눠서 사는 경우도 있는 것을 알게 돼서, 제품 구매 횟수를 Frequency의 기준으로 삼게 됐습니다.
Monetary도 처음에는 3사분위수를 기준으로 나누려고 했지만, vip에 대한 대우는 다른 고객과는 달라야 한다는 것을 알게 돼서, 3사분위수 + 1.5 iqr을 초과하는 고객에게 상위 등급을 부과하게 됐습니다.
RFM 고객 세분화는 CRM을 관리하는 부서에서 기준을 제공받고, 해당 기준에 따라 분류만 해 주는 것이 적합한 것 같습니다.
참조
https://datarian.io/blog/what-is-rfm
RFM 고객 세분화 분석이란 무엇일까요
CRM 타겟팅을 하는 방식 중 가장 범용적으로 사용할 수 있는 RFM 고객 세분화 분석에 대해 알아보겠습니다
datarian.io
https://brunch.co.kr/@d43dde8758de4a9/35
클릭하고 싶은 CRM. 앱 푸시 8가지 법칙 !
CRM 알아가기 시리즈 2편 - 클릭율 높은 푸시의 비밀 | CRM 앱 푸시의 목적은 <CRM 알아가기 시리즈 1편>을 통해서 설명했듯이 일반적으로 푸시, 문자, 메일을 통해서 리텐션을 높이고 구매전환으
brunch.co.kr
'-- Data -- > - 데이터 분석 -' 카테고리의 다른 글
| [ 통계 ] 국민대학교_회귀분석_다중선형회귀분석 + 회귀모형의 진단과 수정 (0) | 2024.08.12 |
|---|---|
| [ kaggle ] cosmetics ecommerce 분석 : 추천 시스템 구현 (0) | 2024.07.29 |
| [ 통계 ] 국민대학교_회귀분석_단순선형회귀분석 (0) | 2024.07.19 |
| [ 통계 ] 국민대학교_회귀분석_상관분석 (0) | 2024.07.19 |
| [ 마케팅 ] 업셀링, 크로스셀링 (0) | 2024.06.03 |
